Video to Speech and Audio Generation
Currently, high-quality, synchronized audio is synthesized using various multi-modal joint learning frameworks, leveraging video and optional text inputs. In the video-to-audio benchmarks, video-to-audio quality, semantic alignment, and audio-visual synchronization are effectively achieved.However, in real-world scenarios, speech and audio often coexist in videos simultaneously, and the end-to-end generation of synchronous speech and audio given video and text conditions are not well studied. Therefore, we propose an end-to-end multi-modal generation framework that simultaneously produces speech and audio based on video and text conditions. Furthermore, the advantages of video-to-audio (V2A) models for generating speech from videos remain unclear. The proposed framework, DeepAudio, consists of a video-to-audio (V2A) module, a text-to-speech (TTS) module, and a dynamic mixture of modality fusion (MoF) module. In the evaluation, the proposed end-to-end framework achieves state-of-the-art performance on the video-audio benchmark, video-speech benchmark, and text-speech benchmark. In detail, our framework achieves comparable results in the comparison with state-of-the-art models for the video-audio and text-speech benchmarks, and surpassing state-of-the-art models in the video-speech benchmark, with WER 16.57% to 3.15% (+80.99%), SPK-SIM 78.30% to 89.38% (+14.15%), EMO-SIM 66.24% to 75.56% (+14.07%), MCD 8.59 to 7.98 (+7.10%), MCD_SL 11.05 to 9.40 (+14.93%) across a variety of dubbing settings.
Ground Truth
Generated Audios
Speech Prompt
Transcription
Generated Speech
But the more forgetfulness had then prevailed, the more powerful was the force of remembrance when she awoke.
Oh, let him come along"! she urged. "I do love to see him about that old house.
Oh, she's always at the piano," said Van. "She must be there now, somewhere," and then somebody laughed.
But in Egypt the traditions of our own and other lands are by us registered for ever in our temples.
Ruth sat quite still for a time, with face intent and flushed. It was out now.
You must look at him in the face - fight him - conquer him with what scathe you may: you need not think to keep out of the way of him.
Her manner was neither independent nor assertive, but rather one of well bred composure and calm reliance.
But, young sharp tongue, now that we have caught you we will put you into a trap that you cannot get out of.
Uncas cast his skin, and stepped forth in his own beautiful proportions.
But don't these very wise things sometimes turn out very foolishly?
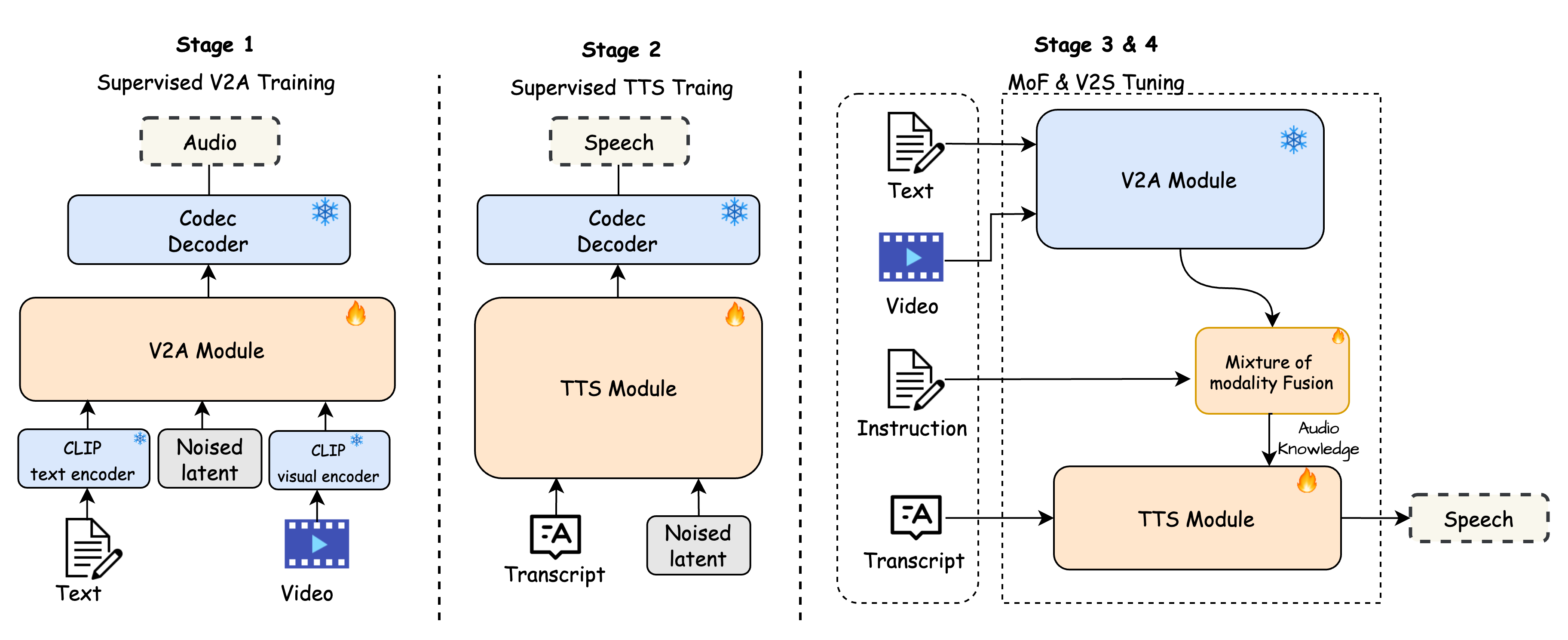
Figure 1: The overview of DeepAudio framework. The proposed DeepAudio framework unifies video-to-audio (V2A) and video-to-speech (V2S) generation in a multi-stage, end-to-end paradigm. The top section illustrates two independent generation paths: (1) The V2A module, which synthesizes ambient audio from video input using a CLIP-based multi-modal feature encoding and a noised latent representation, and (2) The TTS module, which generates speech conditioned on text and noised latent features. Both modules rely on codec decoders to reconstruct high-fidelity outputs. The bottom section presents the MoF module, an integrated multi-modal system that takes text, video, and instructions as inputs. A Gating Network adaptively fuses outputs from the V2A module and the TTS module, ensuring synchronized and context-aware audio-visual generation.
Figure 2: Mel-spectrograms of ground truth and synthesized audio samples from different methods under V2C-Animation Dub 2.0 setting.
| V2S Task | V2C-Animation Dub 1.0 | V2C-Animation Dub 2.0 | V2C-Animation Dub 3.0 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Params | WER(%)↓ | SPK-SIM(%)↑ | EMO-SIM(%)↑ | MCD↓ | MCD_SL↓ | WER(%)↓ | SPK-SIM(%)↑ | EMO-SIM(%)↑ | MCD↓ | MCD_SL↓ | WER(%)↓ | SPK-SIM(%)↑ | |
| GT | 16.10 | 100 | 100 | 0 | 0 | 16.10 | 100 | 100 | 0 | 0 | 10.19 | 100 | |
| HPMDubbing | 69M | 151.02 | 73.64 | 39.85 | 8.59 | 8.32 | 150.83 | 73.01 | 34.69 | 9.11 | 12.15 | 126.85 | 68.14 |
| Speaker2Dub | 160M | 31.23 | 82.15 | 65.92 | 10.68 | 11.21 | 31.28 | 79.53 | 59.71 | 11.16 | 11.70 | 16.57 | 76.10 |
| StyleDubber | 163M | 27.36 | 82.48 | 66.24 | 10.06 | 10.52 | 26.48 | 79.81 | 59.08 | 10.56 | 11.05 | 19.07 | 78.30 |
| Ours-MM-S16K | 493M | 7.16 | 89.20 | 75.27 | 8.02 | 8.11 | 10.29 | 83.83 | 65.70 | 9.33 | 9.43 | 3.17 | 89.30 |
| Ours-MM-S44K | 493M | 6.90 (+74.78%) | 89.22 (+8.17%) | 75.56 (+14.07%) | 7.98 (+7.10%) | 8.07 (+3.00%) | 10.46 (+60.50%) | 83.83 (+5.04%) | 65.65 (+9.95%) | 9.30 | 9.40 (+14.93%) | 3.15 (+80.99%) | 89.38 (+14.15%) |
| Ours-MM-M44K | 957M | 7.24 | 89.12 | 75.37 | 8.01 | 8.10 | 10.24 | 83.78 | 65.83 | 9.31 | 9.41 | 3.15 | 89.39 |
| Ours-MM-L44K | 1.37B | 7.18 | 89.19 | 75.41 | 7.98 | 8.07 | 10.40 | 83.87 | 65.70 | 9.31 | 9.42 | 3.03 | 89.22 |
| Ours-YS-24K | 1.05B | 7.33 | 89.14 | 75.49 | 8.01 | 8.10 | 10.58 | 83.84 | 65.83 | 9.32 | 9.43 | 3.10 | 89.21 |
| V2A Task | VGGSound-Test | TTS Task | LibriSpeech-PC test-clean | ||||||||||
| Params | FAD↓ | FD↓ | KL↓ | IS↑ | CLIP↑ | AV↑ | Params | SIM-O↑ | WER(%)↓ | ||||
| Diff-Foley | 859M | 6.05 | 23.38 | 3.18 | 10.95 | 9.40 | 0.21 | ||||||
| FoleyCrafter w/o text | 1.22B | 2.38 | 26.70 | 2.53 | 9.66 | 15.57 | 0.25 | ||||||
| FoleyCrafter w. text | 1.22B | 2.59 | 20.88 | 2.28 | 13.60 | 14.80 | 0.24 | ||||||
| V2A-Mapper | 229M | 0.82 | 13.47 | 2.67 | 10.53 | 15.33 | 0.14 | GT | 0.665 | 2.281 | |||
| Frieren | 159M | 1.36 | 12.48 | 2.75 | 12.34 | 11.57 | 0.21 | F5-TTS | 336M | 0.648 | 2.508 | ||
| Ours-MM-S16K | 157M | 0.79 | 5.22 | 1.65 | 14.44 | 15.22 | 0.21 | Ours-MM-S16K | 336M | 0.650 | 2.267 | ||
| Ours-MM-S44K | 157M | 1.66 | 5.55 | 1.67 | 18.02 | 15.38 | 0.21 | Ours-MM-S44K | 336M | 0.648 | 2.499 | ||
| Ours-MM-M44K | 621M | 1.13 | 4.74 | 1.66 | 17.41 | 15.89 | 0.22 | Ours-MM-M44K | 336M | 0.648 | 2.510 | ||
| Ours-MM-L44K | 1.03B | 0.97 | 4.72 | 1.65 | 17.40 | 16.12 | 0.22 | Ours-MM-L44K | 336M | 0.647 | 2.175 | ||
| Ours-YS-24K | 718M | 0.74 | 5.69 | 1.69 | 14.63 | 17.70 | 0.24 | Ours-YS-24K | 336M | 0.647 | 2.521 | ||
Table 1: Comparison of different methods on V2S, V2A and TTS tasks. Ours-MM-* represents the V2A module is a reproduced MMAudio series model with specific parameter size and audio sampling rate, while Our-YS-24K represents the V2A module is a reproduced YingSound model. The Params of the Ours-* model refers to the number of actually activated parameters, which depends on the specific task.