Enhance Generation Quality of Flow Matching V2A Model via Multi-Step CoT-Like Guidance and Combined Preference Optimization
1AI Lab, Giant Network
2Zhejiang University
3University of Washington
Abstract
Creating high-quality sound effects from videos and text prompts requires precise alignment between visual and audio domains, both semantically and temporally, along with step-by-step guidance for professional audio generation. However, current state-of-the-art video-guided audio generation models often fall short of producing high-quality audio for both general and specialized use cases. To address this challenge, we introduce a multi-stage, multi-modal, end-to-end generative framework with Chain-of-Thought-like (CoT-like) guidance learning, termed Chain-of-Perform (CoP). First, we employ a transformer-based network architecture designed to achieve CoP guidance, enabling the generation of both general and professional audio. Second, we implement a multi-stage training framework that follows step-by-step guidance to ensure the generation of high-quality sound effects. Third, we develop a CoP multi-modal dataset, guided by video, to support step-by-step sound effects generation. Evaluation results highlight the advantages of the proposed multi-stage CoP generative framework compared to the state-of-the-art models on a variety of datasets, with FAD 0.79 to 0.74 (+6.33%), CLIP 16.12 to 17.70 (+9.80%) on VGGSound, SI-SDR 1.98 dB to 3.35 dB (+69.19%), MOS 2.94 to 3.49 (+18.71%) on PianoYT-2h, and SI-SDR 2.22 dB to 3.21 dB (+44.59%), MOS 3.07 to 3.42 (+11.40%) on Piano-10h.
Demos
Video-to-Audio
Video-to-Piano
Ground Truth
Generated Audios
Method
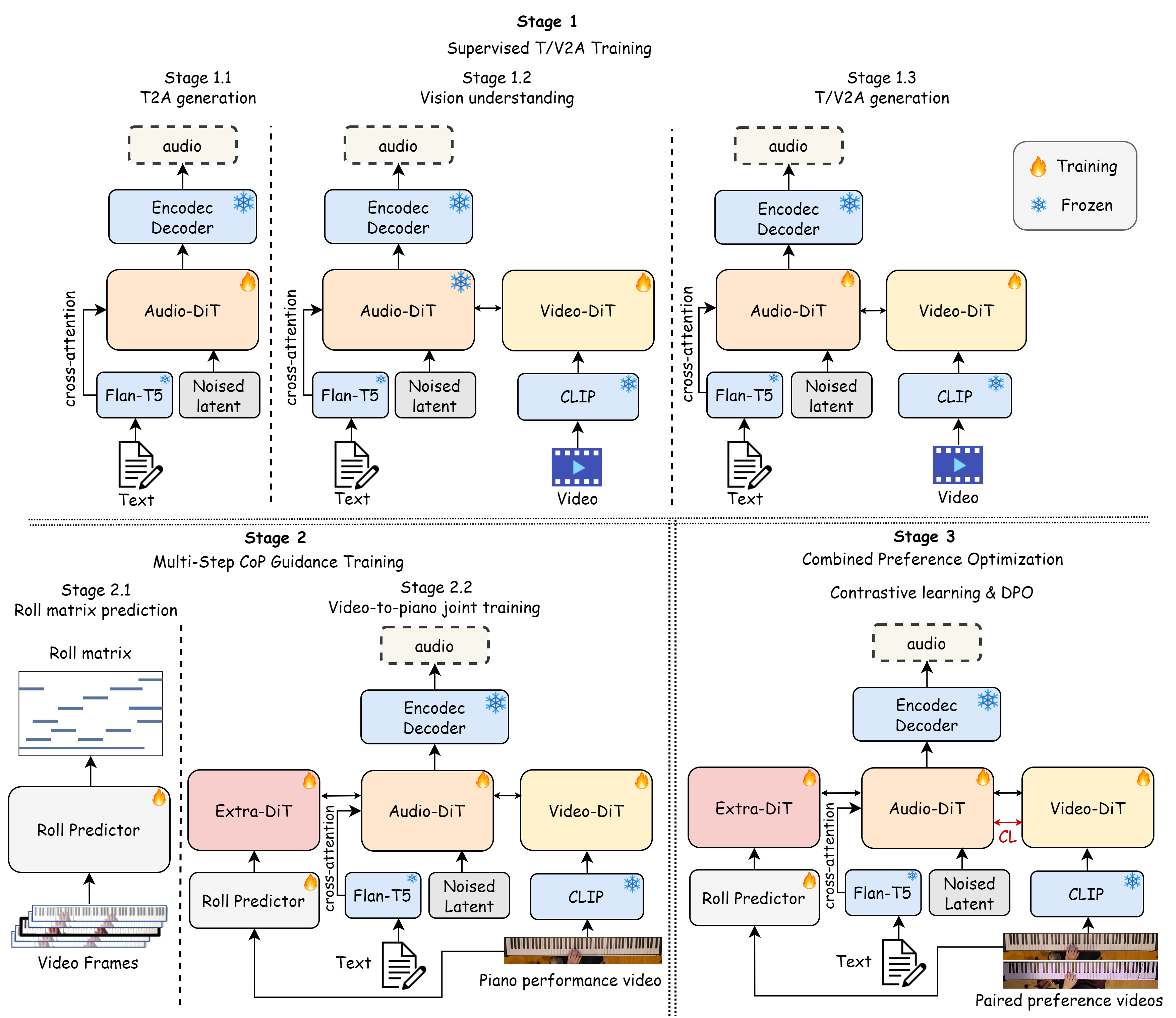
Figure 1: Multi-stage training pipeline of our method.

Figure 2: Five views of the Piano-10h dataset supporting step-by-step generation tasks.
Results
| Method | Params | FAD↓ | FD↓ | KL↓ | IS↑ | CLIP↑ | AV↑ |
|---|---|---|---|---|---|---|---|
| Diff-Foley * | 859M | 6.05 | 23.38 | 3.18 | 10.95 | 9.40 | 0.21 |
| FoleyCrafter w/o text * | 1.22B | 2.38 | 26.70 | 2.53 | 9.66 | 15.57 | 0.25 |
| FoleyCrafter w. text * | 1.22B | 2.59 | 20.88 | 2.28 | 13.60 | 14.80 | 0.24 |
| V2A-Mapper * | 229M | 0.82 | 13.47 | 2.67 | 10.53 | 15.33 | 0.14 |
| Frieren * | 159M | 1.36 | 12.48 | 2.75 | 12.34 | 11.57 | 0.21 |
| MMAudio-S-16kHz | 157M | 0.79 | 5.22 | 1.65 | 14.44 | - | - |
| MMAudio-S-44.1kHz | 157M | 1.66 | 5.55 | 1.67 | 18.02 | - | - |
| MMAudio-M-44.1kHz | 621M | 1.13 | 4.74 | 1.66 | 17.41 | - | - |
| MMAudio-L-44.1kHz | 1.03B | 0.97 | 4.72 | 1.65 | 17.40 | 16.12 * | 0.22 * |
| Ours-Base w/o text | 711M | 0.80 | 8.66 | 2.22 | 12.08 | 16.14 | 0.25 |
| Ours-Base w. text | 711M | 0.78 | 6.28 | 1.73 | 14.02 | 16.86 | 0.25 |
| Ours-Piano2h w. text | 789M | 0.83 | 6.97 | 1.74 | 13.99 | 16.49 | 0.23 |
| Ours-CL w. text | 712M | 0.75 | 6.42 | 1.70 | 14.72 | 17.09 | 0.24 |
| Ours-FactorCL w. text | 718M | 0.74 (+6.33%) | 5.69 | 1.69 | 14.63 | 17.70 (+9.80%) | 0.24 |
Table 1: Objective results of VGGSound-Test regarding audio quality, semantic and temporal alignment. w. text denotes audio generation with text as a guiding condition, and w/o text denotes audio generation without text input, using only the video input. *: These are reproduced using their official checkpoints and inference codes, following the same evaluation protocol.
| Method | SI-SDR↑ | Melody Similarity (MOS)↑ | Smoothness and Appeal (MOS)↑ | MIDI Precision/Recall/Acc/F1 |
|---|---|---|---|---|
| Audeo | 1.98 dB | 2.63 ± 0.10 | 3.25 ± 0.09 | 0.65/0.70/0.51/0.60 |
| Ours-Piano2h w/o guid. | -2.26 dB | 1.68 ± 0.11 | 3.29 ± 0.11 | |
| Ours-Piano2h | 3.35 dB (+69.19%) | 3.44 ± 0.12 (+30.80%) | 3.54 ± 0.11 (+8.92%) |
Table 2: Objective and subjective evaluations on PianoYT-2h. Frame-level MIDI precision, recall, accuracy, and F1 scores are computed following Audeo.